



ABAQUS并行計算CPU利用率低且不穩定,如何提升?
ABAQUS并行計算CPU利用率低且不穩定,設置30核心數并行計算,具體配置及CPU和內存利用率如下圖: 對比6核心,32G內存的筆記本工作站,同一模型(100萬四面體二階單元)計算時間只提升了1/3,感覺這配置效率有點低啊
3917 4 6
L_2194 ??? 3年前
abaqus多核計算CPU利用率?
為什么abaqus多線程計算時 顯示分析采用運動接觸法利用率上不去,罰接觸就可以。有什么辦法可以解決嗎?
2675 1
用點子智慧 ??? 3年前
ABAQUS顯式動力學仿真時CPU占用率和速度提不起來?
之前仿真的時候還是好的,CPU利用率可以提高到100%,速度也挺快;后來在一次仿真中突然最高只能到55%利用率,速度也只有1.6GHz左右,這是怎么回事
2378 1 1
楓林_5897 ??? 1年前
win11運行abaqus6.14.4計算熱傳導時內存利用率低是為啥?
win11運行abaqus6.14.4計算熱傳導時內存利用率低,且遠小于job里設定的極限
2056 1 2
Simon (?。?) ??? 2年前
workbench進行顯示動力學分析時CPU利用率低 
如標題,進行靜力學分析時正常,基本在80%以上,甚至在100%,但是分析動力學就一直上不去,該怎么解決呢
1649
半個一 ??? 3年前
abaqus隱式計算速度提高方法?
我想利用abaqus2022模擬3D打印過程中溫度場的變化情況。以下是我的電腦配置,請問我在提交abaqus作業的時候,cpu數量為多少比較合適。cpus=20時,CPU的利用率為30%。請問有什么辦法能提高嗎?
2552 2 1
用戶_79748 ??? 1年前
【經驗貼】關于影響帶UMAT的ABAQUS模型計算速度的若干因素的探討
4、使用UMAT與否對運行效率的影響編寫了一個線彈性的UMAT,與使用ABAQUS自帶的線彈性材料屬性對比:核心數 位移U 時間 CPU利用率 使用UMAT與否8 0.5 3:35 100% 使用8 0.5 1:55 100% 未使用可見UMAT的使用會降低運算效率。
3096 2 1
EZABAQUS ??? 1年前
ABAQUS用hypermesh劃分網格后導入計算CPU計算的特別慢怎么解決?
ABAQUS子程序計算使用ABAQUS本身的網格劃分計算速率沒問題但是很難達到收斂,因此采用hypermesh進行劃分網格,但是計算效率極其緩慢,CPU占用率一直在10%以內,用ABAQUS本身劃分網格的方法保持其他條件不變的情況下,計算速率沒問題,該怎么解決?有償
3267 4
用戶_110966 ??? 6月前
AMD EPYC 128核心256線程 CPU計算服務器/GPU服務器仿真計算、HPC計算、大數據分析、 
軟件加速:可部署集群管理調度系統,支持橫向擴展;統一管理多節點,CPU 平均使用 率、內存平均使用率;監控集群作業運行狀態,顯示等待作業數、運行作業數、核時、 在線用戶數,集群 CPU 總數等信息;資源監控:提供 CPU 平均利用率,內存平均利用 率,磁盤 IO 速率等信息 11. 操作系統:windows / linux 12.
2879
高性能工作站服務器 ??? 6月前
LS-DYNA參與計算的CPU數目與求解效率詳解 
問題3:計算機上只有1個8核16線程的CPU,在計算LS-DYNA MPP版本的算例時,CPU數目分別使用4、8、16,求解的效率會是線性增長嗎?問題4:計算機上有2個32核64線程的CPU,在計算LS-DYNA MPP版本的算例時,CPU數目分別使用8、16、32、64、128, 求解的效率會是線性增長嗎?問題5:是不是計算時CPU利用率越高,計算效率越高?
4482 5 4
王毅 ??? 2年前
凌炫LE5039單路 XE5049雙路 EPYC 9754/9654/9554/9354工作站塔式服務器主機 仿真計算、HPC計算、有限元分析、CFD、ANSYS、CAE。 
軟件加速:可部署集群管理調度系統,支持橫向擴展;統一管理多節點,CPU平均使用率、內存平均使用率;監控集群作業運行狀態,顯示等待作業數、運行作業數、核時、在線用戶數,集群CPU總數等信息;資源監控:提供CPU平均利用率,內存平均利用率,磁盤IO速率等信息14. 操作系統:支持主流windows、linux、64bit支持虛擬化、VDI、圖形虛擬化、私有云15.
2493 1
高性能工作站服務器 ??? 6月前
成功案例丨仿真+AI技術為快消包裝行業賦能提速:基于 AI 的輕量化設計節省數十億美元 
零部件第二、第三階段屈曲評估 仿真工具:采用 Abaqus 運行的動態顯式模型 計算耗時:使用 64 個高性能 CPU,需 2 小時完成求解 PhysicsAI 模型:基于 180 組仿真結果訓練而成 訓練時間:使用傳統 CPU,耗時 48 小時 吹塑工藝優化(瓶體制作) 仿真工具:采用 Abaqus 運行的動態顯式模型
3161
技術鄰公告 ??? 4月前
智能駕駛域控制器SoC選型 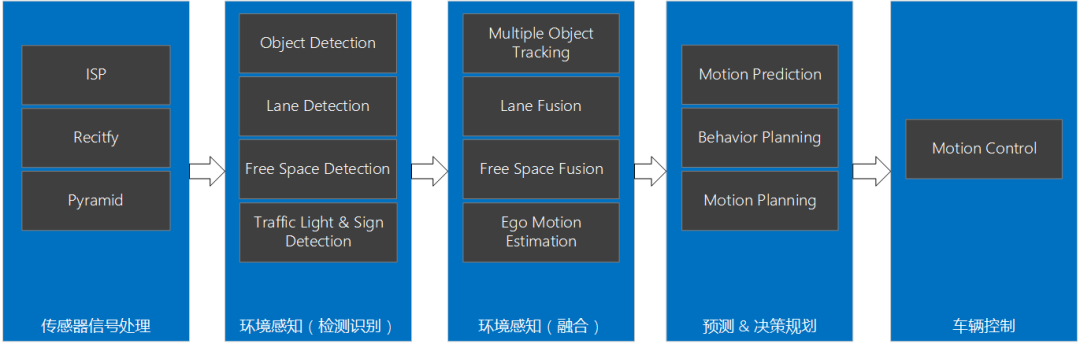
這里就涉及到“算力利用率”的概念。比如說,某個神經網絡模型需要的理論算力是1TOPS,而實際運行的SoC的標稱算力是4TOPS,那么利用率只有25%。以ResNet-50及MobileNet V1網絡在SoC A和SoC B上的運行數據為例,實際的有效算力會因為圖片分辨率、網絡結構差異等原因而不同。這又是什么原因呢?
2765
駕駛哥 ??? 3年前
高分辨率合成孔徑雷達圖像處理SAR工作站硬件配置推薦 
對于高分辨率SAR圖像處理,使用多核CPU和GPU可以顯著提高處理速度。同時,由于高分辨率SAR圖像可能會產生大量數據,因此需要足夠大的內存和存儲容量來處理和存儲這些數據。 算法方面,高分辨率SAR成像使用一系列算法來處理雷達返回的數據,以生成圖像。
2513
UltraLAB ??? 2年前
基于ABAQUS的寒區礦山邊坡危巖穩定性分析 
(3)設備基本參數:CPU為“Intel(R) Xeon(R) CPU i5-6300HQ @ 2.30GHz”;內存為“8.0GB”;顯卡為“Nvdia MX150”,64為驅動系統(4)采用Standard求解器進行模擬;模型利用2D可變形殼型平面模型;用Mohr—Coulomb準則作為破壞準則,利用非對稱矩陣求解器求解,考慮土體自重力。
3379 8 1
雨?? ??? 3年前
一變三Ansys仿真計算加速神器--UltraLAB PCA介紹 
圖1如何更有效的利用超級圖形工作站的四顆Xeon的多核和完美的內存帶寬,發揮最高的計算效能,西安坤隆計算機公司專注高性能計算應用,為此開發的PCA(Parallel Computing Acclerator,并行計算加速器),工作站預裝PCA,大幅提升機器多核并行計算使用率,翻倍提升計算速度。
2508
UltraLAB ??? 3年前
高性能計算:RoCE v2 vs. InfiniBand網絡該怎么選? 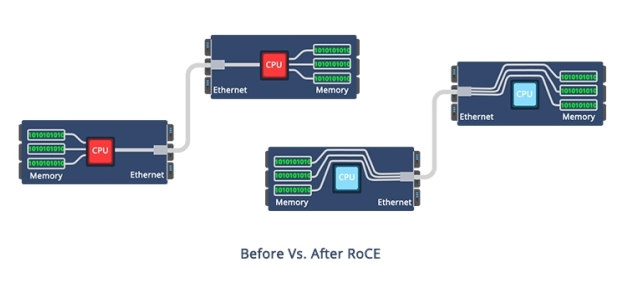
RoCE 規范在以太網上實現了 RDMA 功能,ROCE 需要無損網絡,RoCE的主要優勢在于它的延遲較低,因此可提高網絡利用率;同時它可避開TCP/IP 并采用硬件卸載,因此 CPU 利用率也較低。新 RoCEv2 標準可實現 RDMA 路由在第三層以太網網絡中的傳輸。RoCEv2 規范將用以太網鏈路層上的 IP 報頭和 UDP 報頭替代 InfiniBand 網絡層。
3358
牛頓家的計算機 ??? 3年前
各向同性硬化von Mises率無關彈塑性本構理論以及umat源代碼 
Abaqus設置的材料參數為,彈性部分的性質:塑性部分的性質:umat設置相同的材料參數為:以及需要設置狀態變量的個數為8。二者計算的結果對比如下:二者等效塑性應變的演化對比圖如下:二者塑性耗散的演化對比圖為:4.2 帶孔板拉伸實驗利用相同的材料性質計算一帶孔板的拉伸實驗。
3315 6 1
dearjj ??? 2年前
FCBGA封裝的 CPU 芯片散熱性能影響因素研究 
圖1為某國產CPU平 臺 和Intel CPU平臺近三代 CPU的熱設計功耗TDP(Thermal Design Power)增長趨勢圖。從圖1可以看出,其功耗年增長率接近20%。同時,芯片集成化和小封裝的需求也不斷增長,這就導致了芯片的功率密度(單位面積的功耗)越來越高,因此芯片散熱問題日趨嚴峻。
4745
熱管理博覽會 ??? 3年前
800億晶體管GPU、144核CPU來了 
前面說的Grace CPU超級芯片系列、去年發布的Grace Hopper超級芯片都采用了這一技術來連接處理器芯片。 NVIDIA超大規模計算副總裁Ian Buck認為:“為應對摩爾定律發展趨緩的局面,必須開發小芯片和異構計算。” 因此,英偉達利用其在高速互連方面的專業知識開發出統一、開放的NVLink-C2C互連技術。
2511
平頭叔 ??? 4年前
20條/頁 
 17
17 跳至頁

技術鄰APP
工程師必備
工程師必備
- 項目客服
- 培訓客服
- 平臺客服
TOP
